| 首页| 科学研究| 学术前沿 |
| 陈宝国教授团队在Journal of Memory and Language发文揭示自然阅读中预期性效应的函数形式 |
| 发布时间:2026-06-18 作者: 浏览量: 【关闭】 |
|
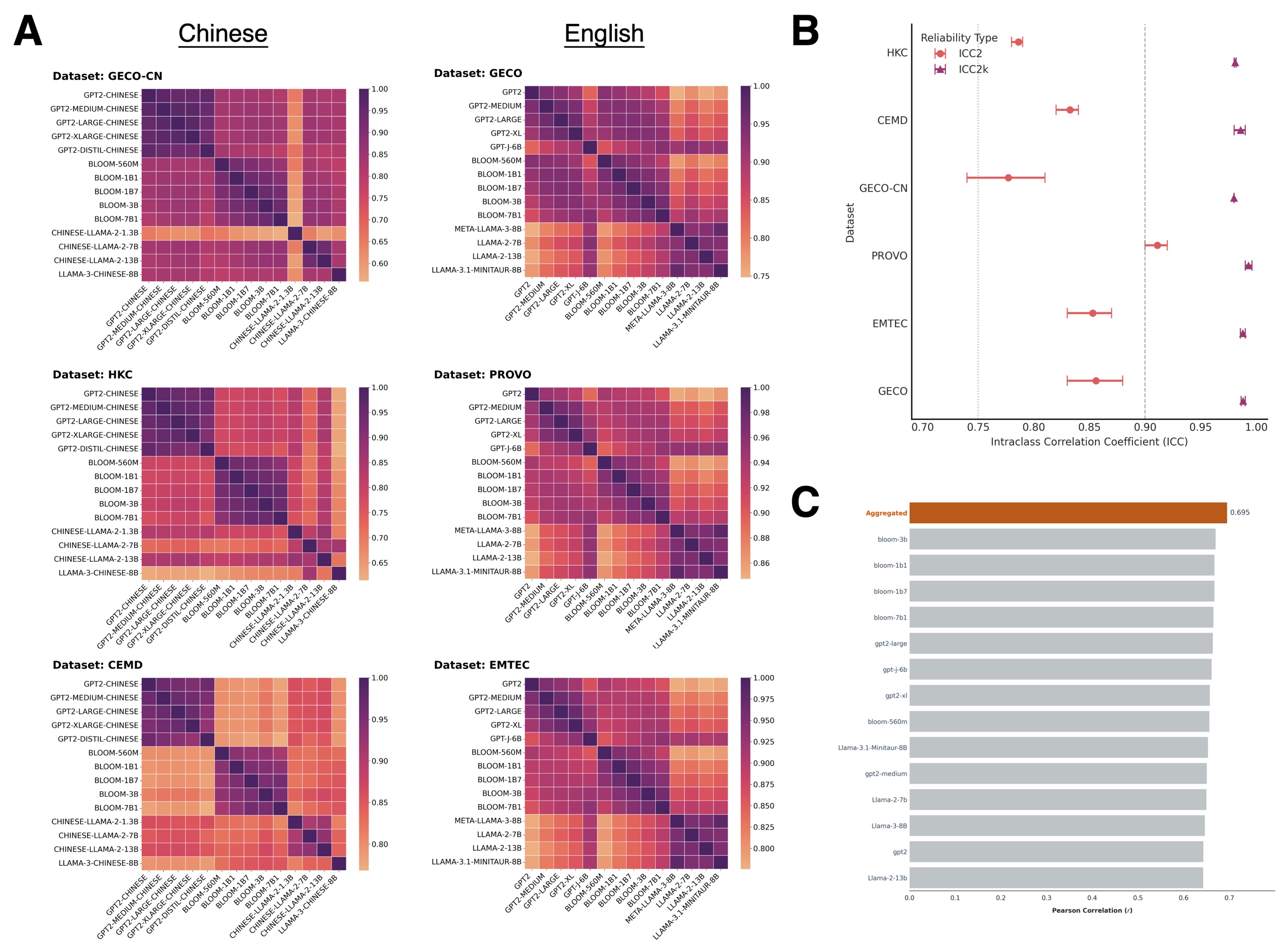
读到“她打开冰箱,拿出了一瓶__”,你似乎已经想到了空白处的词:“牛奶”“矿泉水”或“果汁”。当这些词真正出现时,阅读过程会十分流畅。但如果出现的词是“香水”呢?你会愣上一愣:语法是正确的,意思也没有问题,但总觉得不对劲儿。这种落差,正是预期性效应的体现:越容易被预测的词,读起来越省力。这一效应是语言理解研究中最稳健的发现之一,但它背后的认知机制长期悬而未决:读者到底是精准预测了某个具体词汇,还是始终在权衡所有可能的文本走向,并在“意外”到来时付出代价? 近日,陈宝国教授团队在心理语言学旗舰期刊 Journal of Memory and Language 发表研究成果,揭示预期性效应的函数形式遵循线性与对数函数的加法组合,为阅读中“预激活”与“概率推理”两种认知机制的共存提供了证据。 预激活假说认为,读者在阅读时会根据上下文预先激活特定词汇,若实际出现的词与预激活表征匹配,识别得就快;由于预激活正确的可能性与该词的条件概率成正比,因此实际加工时间与词汇出现概率呈线性关系。而惊异度理论(Surprisal Theory)认为,阅读并非对离散词汇的预期,而是对整体文本解读的概率推理,包含了接下来句子展开的各种可能形式。随着每个新词出现,读者对可能文本解读的概率分布不断更新,更新所产生的认知代价与词汇惊异值(即香农信息量,定义为条件概率的负对数)呈线性关系,换算回概率尺度则为对数关系。两种理论均有实验证据的支持,呈现出相互矛盾的局面。 上述两种机制能否共存?若能共存,预期性效应应表现为线性与对数成分的加法组合。针对这一问题,研究者依托6套大规模中英文自然阅读眼动追踪数据,结合来自23个大语言模型(LLMs)的词语惊异值估计,对预期性效应的线性、对数、加法及加权四种函数形式进行了系统比较。 由于不同LLMs在预训练语料、架构和参数量等方面上存在差异,所以其预期性估计可能会产生系统偏差。分析发现,语言模型之间的相关性热图呈现出模型家族聚类结构,表明模型间的差异并非随机误差,而是来自特定模型家族的系统性特征。基于此,研究者对LLMs的估计进行聚合,发现聚合估计与读者填充测验所得到的预期性评定在一致性上优于任意单一模型,说明聚合方法的有效性。
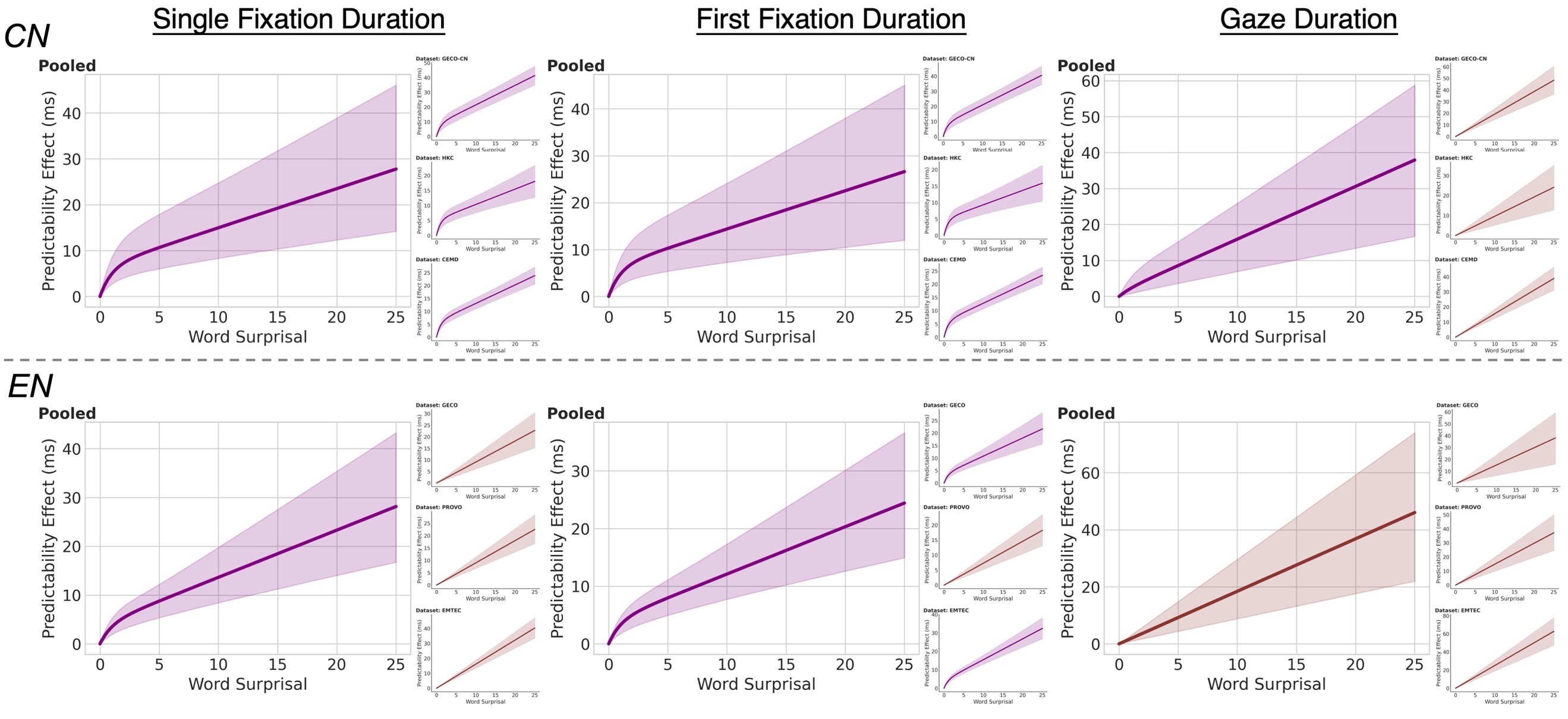
图1. 14个大型语言模型预期性估计的相似性与聚合效果 函数形式比较的结果发现,预期性效应的曲线形状,是两种机制叠加的结果。读者始终保持着对接下来文本走向的概率推断,每遇到一个新词就随之更新,这一过程表现为对数函数;与此同时,当某个词的预期性很高、读者很容易猜到它时,其识别便会受到促进,这一过程表现为线性函数。
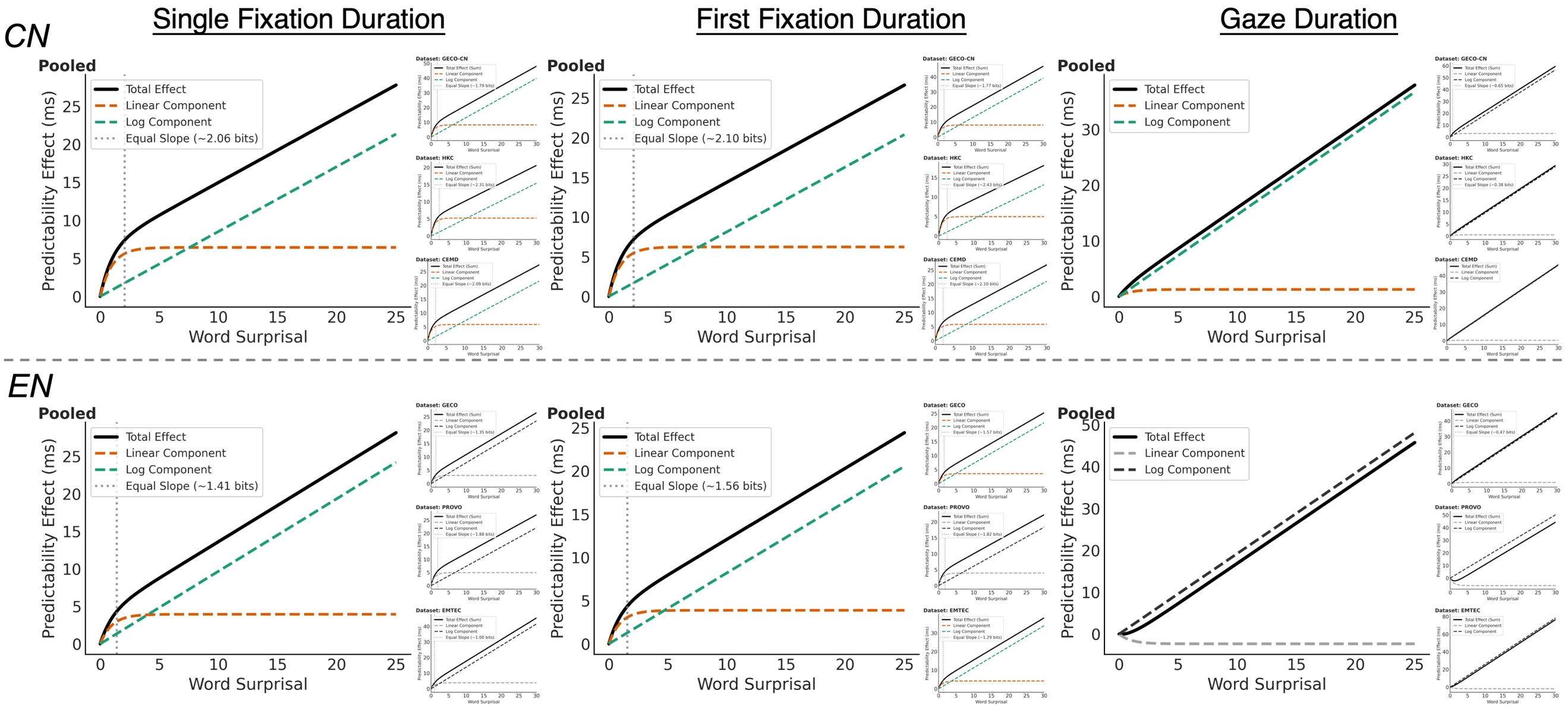
图2. 预期性效应在各眼动指标下的函数形态。主图为合并分析结果,子图为各数据集单独结果。 进一步分解加法模型的内部参数,研究发现,两种机制在中英文读者之间的“配比”存在差异,中文读者的“预激活”效应比英文读者更强、持续更久。研究者认为,这与中文书写的特殊性有关:中文没有词与词之间的空格。所以对于中文读者而言,认出一个词的同时,还需要判断这个词从哪里开始、到哪里结束。提前猜到接下来的词,不仅能加速识别,还能帮助划定词语边界,这让“预激活”在中文阅读中具有更大的价值,所以读者对其更加依赖。
图3. 相加函数的两个成分的效应分解。实线为相加函数,虚线为线性成分与对数成分。 综上,研究结果表明,阅读中的预期性效应是两套认知机制的协作,而非单一过程。现有主流英文和中文眼动控制计算模型(如E-Z Reader模型和中文阅读模型)均只考虑了预激活机制,未来的模型应将两者都纳入,才能更准确地解释真实的阅读过程。 北京师范大学心理学部博士研究生李骁轩为论文第一作者,西南大学心理学部博士研究生赵潇田参与了本研究,陈宝国教授为通讯作者。 论文信息: Li, X., Zhao, X., & Chen, B. G. (2026). The predictability effect in natural reading follows an additive combination of linear and logarithmic functional form: cross-language evidence from English and Chinese. Journal of Memory and Language, 149, 104766. https://doi.org/10.1016/j.jml.2026.104766
|
|